
支持向量机(Support Vectors Machine)的原理和部分数学推导。
Support Vector Machine
1. Seperable case
超平面(Hyperplane): 在p维空间中的p-1维子空间,将p维空间分成两部分
线性可分: 存在一个超平面将所有样本点分离,即满足
最大间隔超平面(maximal margin hyperplane): 若样本线性可分,将样本分离的超平面不唯一。计算所有样本点与超平面之间的距离,其最小值也称为边缘(margin),则定义最大间隔超平面为有最大边缘的超平面。(离超平面最近的样本点有“最宽的间隔”)
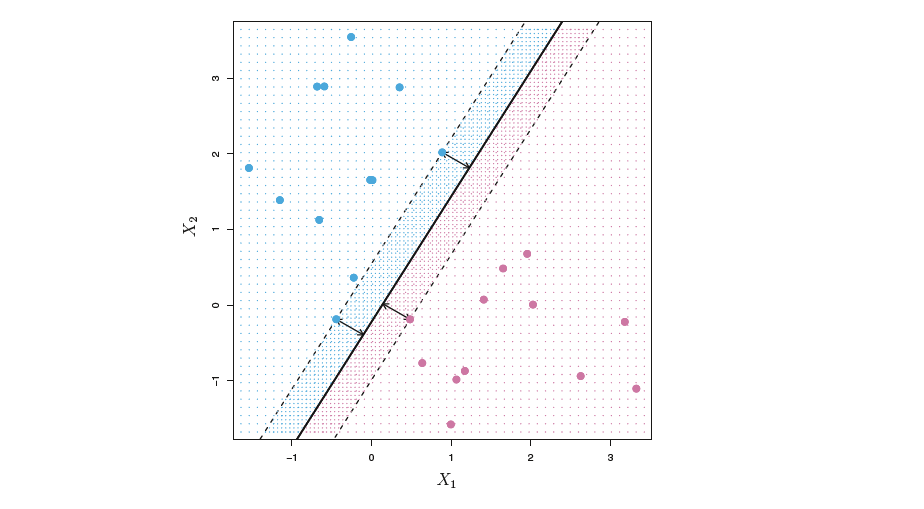
支持向量(support vectors): 距离最大间隔超平面最近的样本点,也即“边缘”上的样本点。支持向量确定了超平面的位置,故称之“支持”向量。
(该分类器由支持向量确定,因而对于支持向量非常敏感。另外,margin具体大小可以用于衡量分类器的可信程度,更宽的margin更可信)
于是通过下式构造最大间隔超平面,即最大间隔分类器(maximal margin classifier):
其中$M>0$也即margin.
2. Inseperable case
若样本线性不可分,则无法定义最大间隔超平面。推广至构造“几乎分隔”的平面,称这种情况下得到的分类器为支持向量分类器(support vector classifier)
另一方面,线性可分的样本使用最大间隔超平面可能存在过拟合的情况。支持向量分类器(也称soft margin classifier)允许分类器将小部分样本分到错误的一侧,定义如下:
其中$C\geq 0$为参数,$M$即margin.
$\epsilon_1,…,\epsilon_n$为松弛变量(slack variables)允许样本分类到错误的一侧。当$\epsilon_i=0$时,对于样本$x_i$分类正确。也即$\epsilon_i$确定了样本$x_i$的位置,$\epsilon_i>0$则对应样本分类到错误的一侧(violate the margin),值越大则离平面越远。
则通过控制参数$C$就可以调节边缘的“松紧”程度。$C$越大则允许更多的样本分类到错误的一侧,对应的$M$更大(边缘更宽)。
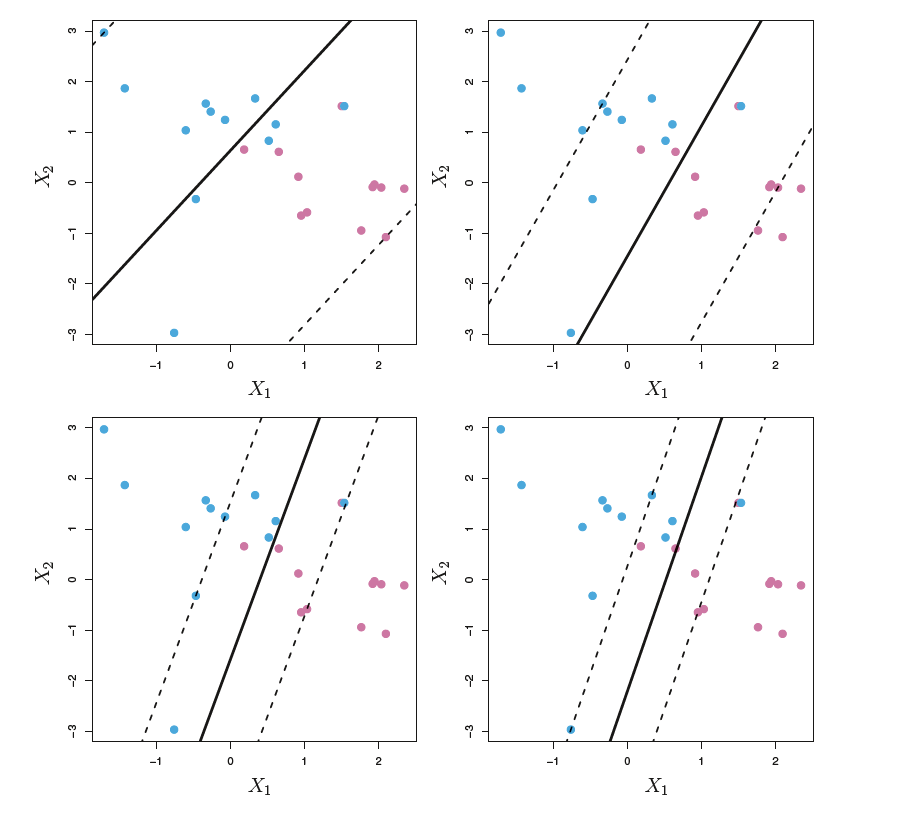
支持向量(support vectors): 落在边缘上以及被允许错误分类的样本组成支持向量。可见支持向量分类器只取决于支持向量,边缘外正确分类的样本位置变动(在边缘外变动)不影响分类器。
- $C$越大边缘越宽,支持向量更多,low variance and high bias
- $C$越小边缘越窄,支持向量更少,high variance and low bias
Note: 此处参数$C$与下面的等价优化问题中的参数含义不同,注意区分理解,上面的参数$C$为$\sum_i\epsilon_i\leq C$而下面的等价问题是$\min_{\beta_0,\beta}\frac{1}{2}||\beta||^2+C\sum_i\epsilon_i$
由此可见,支持向量分类器的决策只依赖于训练样本的一个子集(支持向量),相较于LDA而言有更好的稳定性。(LDA依赖于各类中所有样本)
支持向量分类器最优化问题求解:
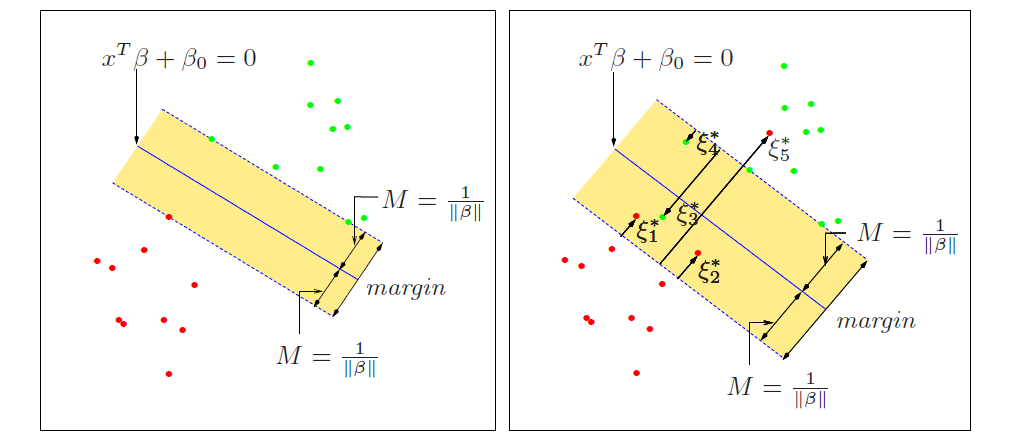
由于边缘宽度由边缘上的支持向量决定,支持向量满足:
且有支持向量距离超平面距离为:
因而可以确定有$\max_{\beta,\epsilon,M} M=\frac{1}{||\beta||}$. 因而优化问题转化为:
等价的最优化问题:
由拉格朗日形式:
得到KKT条件:
可以得到拉格朗日对偶函数:
于是原优化问题转化为:
假设$\alpha$是优化问题的解,则$\beta=\sum_i\alpha y_ix_i$,又因为$\alpha_i[y_i(\beta_0+x_i^T\beta)-(1-\epsilon_i)]=0$,则若$\alpha_i>0$必有$y_i(\beta_0+x_i^T\beta)-(1-\epsilon_i)=0$,即只有支持向量对应的$\alpha_i$为正。下记$sv$为支持向量的空间。
求得最优解$\alpha$后,可计算$\beta=\sum_{i\in sv}\alpha y_ix_i$,由支持向量可以计算$\beta_0$取平均为:
从而得到超平面为$f(x)=\beta_0+x^T\beta=\beta_0+\sum_{i\in sv}\alpha_iy_i(x^Tx_i)$
如何求解?
参考SMO算法
3. Support Vector Machines
支持向量分类器使用了线性边界,然而对于多数数据而言不存在线性的关系,(如经典的“异或”)需要使用非线性的边界。
和其他线性模型相似地,可以利用基函数(如polynomials和splines)扩展特征空间。
思路:使用非线性映射,将原始数据映射到更高维的空间里,在高维空间下找到最佳分离超平面。
3.1 Polynomial
quadratic: 对于p维特征空间$X_1,…,X_p$,则用2p维$X_1,X_1^2,…,X_p,X_p^2$向量构造特征向量分类器:
3.2 The Support Vector Machine
“kernel trick” 使用核函数规避了维数灾难问题。
核函数(kernels): $K(x,y)=\langle h(x),h(y)\rangle$且核函数满足对称性,半正定性。这里给定$K$不需要知道$h$的具体形式
回顾支持向量分类器最优化问题中,拉格朗日对偶形式为:
若由核函数对特征空间进行映射,对应:
其中$H_{ij}=y_iy_jK(x_i,x_j)$. 最终解得超平面为$f(x)=\beta_0+\sum_i\alpha_iy_i\langle h(x),h(x_i)\rangle$
一些常用的核函数:

Reference:
- The Elements of Statistical Learning
- Introduction to Statistical Learning with R