
应用回归分析课程内容整理,参考教材:Applied Linear Statistical Models 5e by Kutner
Chap1 Linear Regression with One Predictor Variable
Outline:
- Relations between variables
- Concepts in Regression Models
- random error
- residuals
- Simple Linear Regression Model with Distribution of Error Terms Unspecified
- Least square estimators(LSEs)
- Properties of LSEs
- Normal Error Regression Model
1.1 Relations between Variables
Functional Relation: $Y=f(X)$
Statistical Realtion: $Y=f(X)+\epsilon$
1.2 Concepts in Regression models
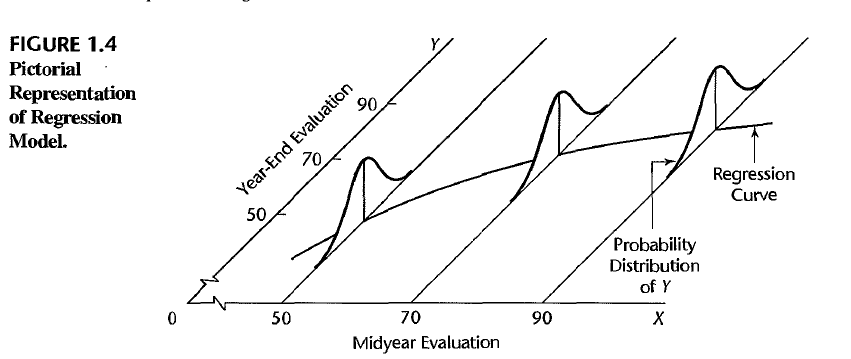
A regression model is a formal means of expressing the two essential ingredients of a statistical relation:
- A tendency of the response variable $Y$ to vary with the predictor variable $X$ in a systematic fashion (There is a probability distribution of $Y$ for each level of $X$)
- A scattering of points around the curve of statistical relationship (The means of these probability distributions vary in some systematic fashion with $X$)
Two distinct goals:
- (Estimation) Understanding the relationship between predictor variables and response variables
- (Prediction) Predicting the future response given the new observed predictors
Note: Always need to consider scope of the model, and statistical relationship generally does not imply causality.
1.3 Simple Linear Regression Model with Distribution of Error Terms Unspecified
where $\epsilon_i\sim N(0,\sigma^2)$, $\epsilon_i$ and $\epsilon_j$ are uncorrelated. $X_i$ is a fixed known constant and $\beta_0,\beta_1,\sigma^2$ are unknown parameters.
The response $Y_i$ = deterministic term + random term, which implies that $Y_i$ is a random variable:
Alternative form:
1.4 Data for Regression Analysis
- Obeservational Data
- Experimental Data
- Completely Randomized Design
1.5 Overview of Steps in Regression Analysis
1.6 Estimation of Regression Function
1.6.1 Method of Least Squares
We are aiming to make $Y_i$ and $\beta_0+\beta_1 X_i$ close for all $i$, here we use Least Squares Estimation, which is
Then find the least square estimators $b_0,b_1$ that minimize $Q$
Then we can find the estimators
True regression line is $Y=\beta_0+\beta_1X$, we have $\hat{Y}=b_0+b_1X$, and $E(b_0)=\beta_0,E(b_1)=\beta_1$
Residual: the difference between the observed and fitted predicted value. $e_i=Y_i-\hat{Y_i}=Y_i-(b_0+b_1X_i)$.
Model error: $\epsilon_i=Y_i-E(Y_i)=Y_i-(\beta_0+\beta_1X_i)$
Sum of Squared Residuals: $SSE=\sum_{i=1}^ne_i^2=\sum_{i=1}^n(Y_i-\hat{Y_i})^2$
The fitted values are calculated by
1.6.2 Properties of Fitted Regression Line
- $\sum_{i=1}^ne_i=0$
- $\sum_{i=1}^ne_i^2$ is minimized
- $\sum_{i=1}^nY_i=\sum_{i=1}^n\hat{Y_i}$
- $\sum_{i=1}^nX_ie_i=0$
- $\sum_{i=1}^n\hat{Y_i}e_i=0$
Proof:
(1) $\sum_{i=1}^ne_i=\sum_{i=1}^n[Y_i-\bar{Y}-b_1(X_i-\bar{X})]=0\Rightarrow$ (3) $\sum_{i=1}^nY_i=\sum_{i=1}^n\hat{Y_i}$
(4) $\sum_{i=1}^nX_ie_i=\sum_{i=1}^n(X_i-\bar{X})e_i=\sum_{i=1}^n(X_i-\bar{X})[Y_i-\bar{Y}-b_1(X_i-\bar{X})]=SS_{XY}-b_1SS_{XX}=0$
(5) $\sum_{i=1}^n\hat{Y_i}e_i=\sum_{i=1}^ne_i[\bar{Y}+b_1(X_i-\bar{X})]=\bar{Y}\sum_{i=1}^ne_i+b_1\sum_{i=1}^ne_i(X_i-\bar{X})=0$
1.7 Estimation of Error Terms Variance $\sigma^2$
$\epsilon$ is unobservable, so we use residual $e$ to estimate $\epsilon$
Properties of Estimators:
Under linear regression model in which the errors have expectation zero and are uncorrelated and have equal variance $\sigma^2$.
- Least squares estimators $b_0$ and $b_1$ are linear combinations of $\left\{Y_i\right\}$
- (Gauss-Markov theorem) Least squares estimators $b_0$ and $b_1$ are BLUE (best linear unbiased estimators) of $\beta_0$ and $\beta_1$ respectively
- MSE is an unbiased estimator of $\sigma^2$, i.e.$E(MSE)=\sigma^2$
Proof:
1- Linear combinations of $Y_i$
here we have
2- Best Linear Unbiased Estimator
Denote $k_i=\frac{X_i-\bar{X}}{SS_{XX}}$, note that $\sum_{i=1}^nk_i=0,\sum_{i=1}^nk_iX_i=1,\sum_{i=1}^nk_i^2=\frac{1}{SS_{XX}}$.
$E(b_1)=\sum_{i=1}^nk_iE(Y_i)=\sum_{i=1}^nk_i(\beta_0+\beta_1X_i)=\beta_0\sum_{i=1}^nk_i+\beta_1\sum_{i=1}^nk_iX_i=\beta_1$
$E(b_0)=E(\bar{Y}-b_1\bar{X})=(\beta_0+\beta_1\bar{X})-\beta_1\bar{X}=\beta_0$
So $b_0$ and $b_1$ are unbiased estimators of $\beta_0$ and $\beta_1$.
$var(b_1)=\sum_{i=1}^nk_i^2var(Y_i)=\sigma^2\sum_{i=1}^nk_i^2=\frac{\sigma^2}{SS_{XX}}$
$cov(b_1,Y_i)=cov(\sum_{i=1}^nk_iY_i,Y_i)=cov(k_iY_i,Y_i)=k_i\sigma^2$
$cov(b_1,\bar{Y})=cov(b_1,\sum_{i=1}^n\frac{1}{n}Y_i)=\frac{1}{n}\sum_{i=1}^nk_i\sigma^2=0$
$var(b_0)=var(\bar{Y}-b_1\bar{X})=var(\bar{Y})+\bar{X}^2var(b_1)-2\bar{X}cov(\bar{Y},b_1)=\sigma^2(\frac{1}{n}+\frac{\bar{X}^2}{SS_{XX}})$
$cov(b_0,b_1)=cov(\bar{Y}-b_1\bar{X},b_1)=-\bar{X}var(b_1)=-\frac{\bar{X}}{SS_{XX}}\sigma^2$
The variance matirx of $(b_0,b_1)$ is
Among all unbiased linear estimators of the form $\hat{\beta_1}=\sum c_iY_i$
so that it must be the case that $\sum c_i=0$ and $\sum c_iX_i=1$.
Define $d_i=c_i-k_i$, where $k_i=\frac{X_i-\bar{X}}{SS_{XX}}$
Now by showing that
So that
when $d_i=0$, the variance is minimized.
#TODO:Similarly, we can show $b_0$ is BLUE of $\beta_0$.
3- $E(MSE)=\sigma^2$
$e_i=Y_i-\hat{Y_i}=(Y_i-\bar{Y})-b_1(X_i-\bar{X})$
$E(e_i)=E(Y_i-b_0-b_1X_i)=\beta_0+\beta_1X_i-\beta_0-\beta_1X_i=0$
$E(SSE)=\sum_{i=1}^nE(e_i^2)=\sum_{i=1}^nvar(e_i)=(n-1)\sigma^2-\sigma^2=(n-2)\sigma^2$
$E(MSE)=\frac{E(SSE)}{n-2}=\sigma^2$
Note: For any $i\not ={j}$, $\epsilon_i$ and $\epsilon_j$ are uncorrelated, but $e_i$ and $e_j$ are correlated.
It can be proved that
So that
1.8 Normal Error Regression Model
1.8.1 Method of Least Sqaures
where $\epsilon_i$ are i.i.d and $\epsilon_i\sim N(0,\sigma^2)$, so that $Y_i\sim N(\beta_0+\beta_1X_i,\sigma^2)$ and $\left\{Y_i\right\}$ are independent
Likelihood:
Use method of least square to find the Maximum Likelihood Estimators (MLEs):
then the MLEs are
1.8.2 Properties of MLEs
1- MLEs of $\beta_0$ and $\beta_1$ are same with LSE estimators $b_0$ and $b_1$. They are linear combinations of $\left\{Y_i\right\}$
2- MLEs of $\beta_0$ and $\beta_1$ are BLUEs and normal distributed
3- MLE of $\sigma^2$ is a biased estimator with
3- $(\hat{\beta_0},\hat{\beta_1},\bar{Y})$ and $\sigma^2$ are independent.
Proof:
4- This can be derived by Fisher’s theorem
then we have
With the Fisher’s theorem
Chap2 Inference in Regression and Correlation Analysis
Outline:
- Inferences Concerning $\beta_1,\beta_0$ and $EY$ in Normal Error Regression Model
- Prediction Interval of New Observation
- Confidence Band for Regression Line
- Analysis of Variance (ANOVA) approach to Regression Analysis
- General linear test approach
- Normal Correlation Models and Inferences
2.1 Inferences Concerning $\beta_1$
with $\epsilon_i$ are i.i.d and $\epsilon_i\sim N(0,\sigma^2)$.
since
where $\sigma\left\{b_1\right\}=\sqrt{\sigma^2/SS_{XX}},s\left\{b_1\right\}=\sqrt{MSE/SS_{XX}}$
2.2 Inferences Concerning $\beta_0$
since
where $\sigma\left\{b_0\right\}=\sqrt{\sigma^2(\frac{1}{n}+\frac{\bar{X}^2}{SS_{XX}})},s\left\{b_1\right\}=\sqrt{MSE(\frac{1}{n}+\frac{\bar{X}^2}{SS_{XX}})}$
2.3 Some Considerations on Making Inferences
- Effects of departures from normality of the $Y_i$
- Spacing of the $X$ levels
- Power of Tests
2.4 Interval Estimaton of $E\left\{Y_h\right\}$
Intersted in estimating the mean response for particular $X_h$
The unbiased point estimator of $E\left\{Y_h\right\}$
$\hat{Y_h}=b_0+b_1X_h=\bar{Y}+b_1(X_h-\bar{X})$
$E(\hat{Y_h})=\beta_0+\beta_1X_h=E(Y_h)$
$var(\hat{Y_h})=var(\bar{Y})+(X_h-\bar{X})^2var(b_1)=\sigma^2(\frac{1}{n}+\frac{(X_h-\bar{X})^2}{SS_{XX}})$
So we have
since
where $s\left\{\hat{Y_h}\right\}=\sqrt{MSE(\frac{1}{n}+\frac{(X_h-\bar{X})^2}{SS_{XX}})}$
2.5 Prediction of New Observation
Intersted in predicting new observation when $X=X_h$
here $Y_{hn}\perp\left\{Y_1,…,Y_n\right\}$ and
Prediction of $Y_{hn}$
Prediction error
since
where $s\left\{pred\right\}=\sqrt{MSE(1+\frac{1}{n}+\frac{(X_h-\bar{X})^2}{SS_{XX}})}=\sqrt{MSE+s^2\left\{\hat{Y_h}\right\}}$
2.6 Confidence Band for Regression Line
The $(1-\alpha)\times100\%$ Confidence interval of $E(Y_h)=\beta_0+\beta_1X_h$
The Working-Hotelling Confidence Band
Replace $t(1-\alpha/2,n-2)$ with Working-Hotelling value $W$ in each confidence interval
#TODO: It can be proved that
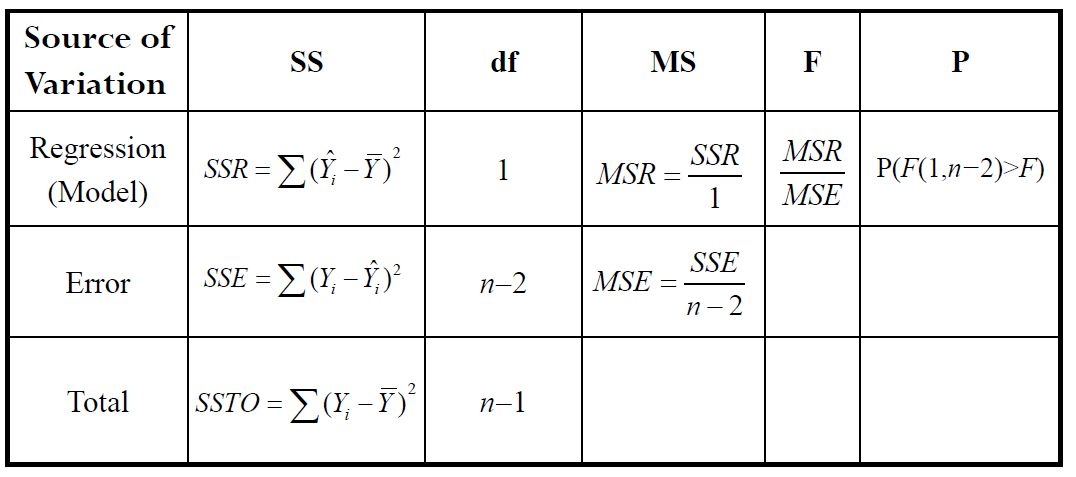
2.7 ANOVA Approach to Regression
ANOVA: Analysis of Variance, it can be described with the deviation of observation $Y_i$ around the fitted line (i.e.$Y_i-\hat{Y_i}$) and the deviation of fitted value $\hat{Y_i}$ around the mean (i.e.$\hat{Y_i}-\bar{Y}$).
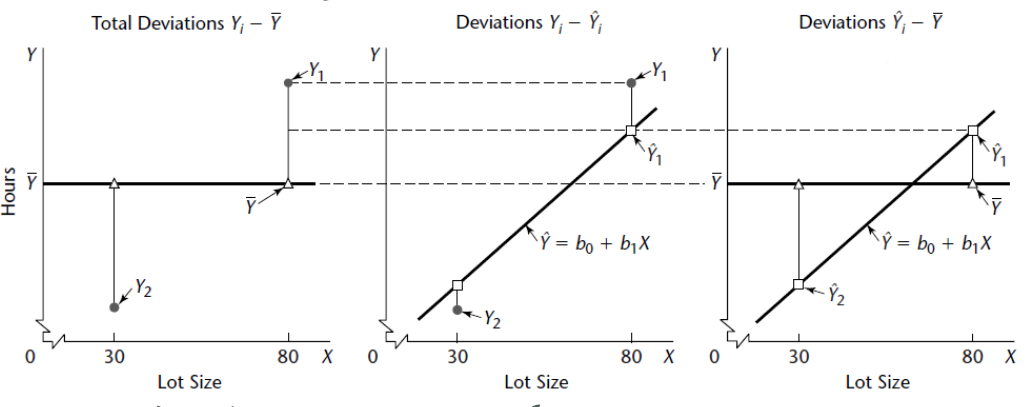
2.7.1 Partitioning of Total Sum of Squares
Because we have
then
SSTO: The total sum of squares
SSR: The sum squares explained by regression
SSE: The sum squares explained by residual
In normal error regression model, we have
Under $H_0:\beta_1=0$
Generally,
1- $\dfrac{SSE}{\sigma^2}\sim\chi^2_{n-2,0}$
2- $\dfrac{SSR}{\sigma^2}=\dfrac{b_1^2}{\sigma^2/SS_{XX}}\sim\chi^2_{1,\delta}$, where $\delta=\dfrac{\beta_1^2}{\sigma^2/SS_{XX}}$, since $b_1\sim N\left(\beta_1,\frac{\sigma^2}{SS_{XX}}\right)$
3- $SSR\perp SSE$
So that $\dfrac{SSTO}{\sigma^2}\sim\chi^2_{n-1,\delta}$
2.7.2 Mean Squares
$E(MSR)=E(SSR)=E(b_1^2SS_{XX})=SS_{XX}(\frac{\sigma^2}{SS_{XX}}+\beta_1^2)=\sigma^2+\beta_1^2SS_{XX}$
$E(MSE)=\sigma^2$
2.7.3 F test
Hypothesis: $H_0:\beta_1=0\quad v.s.\quad H_1:\beta_1\not ={0}$
When $H_0$ is false, $MSR>MSE$. Reject $H_0$ when $F^*$ large.
2.7.4 Equivalence of F test and two-sided t-test
Hypothesis: $H_0:\beta_1=0\quad v.s.\quad H_1:\beta_1\not ={0}$
In addition:
Equivalence of rejection regions:
2.8 General Linear Test Approach
Full/unrestricted model: $Y_i=\beta_0+\beta_1X_i+\epsilon_i$
Reduced/restricted model: $Y_i=\beta_0+\epsilon_i\quad Y_i\sim N(\beta_0,\sigma^2)$
Intuition: Compare the SSE’s of the two models to find out which model fits better. If SSE(F) not much smaller than SSE(R), full model doesn’t better explain Y.
Hypothesis: $H_0:\text{Reduced model}\quad v.s.\quad H_1:\text{Full model}$
Test statistic:
since $SSE(R)=(SSE(R)-SSE(F))+SSE(F)$, the degree of freedom can be calculate with Fisher’s Theorem.
Note: General linear test is equal to ANOVA test
$SSE(F)=SSE$
$SSE(R)=\sum(Y_i-\hat{Y_i}(R))^2=\sum(Y_i-\bar{Y})^2=SSTO,df_R=n-1$
2.9 Descriptive Measures of Linear Association
Coefficient of Determination:
which is the proportion of total variation $Y$ explained by $X$
Pearson’s Correlation Coefficient:
which measures the strength of the linear relationship between two variables
$\rho$ can be estimated by
For simple linear regression
2.11 Normal correlation model
Note: In normal error regression model, we assume that the X values are known constants. A correlation model, takes each variable as random.
2.11.1 Bivariate Normal Distribution
The normal correlation model for the case of two variables is based on the bivariate normal distribution $N(\mu_1,\mu_2,\sigma^2_1,\sigma^2_2,\rho)$.
Density function:
Marginal Distribution:$Y_1\sim N(\mu_1,\sigma_1^2), Y_2\sim N(\mu_2,\sigma_2^2)$
Conditional Probability:
2.11.2 Inference on $\rho_{12}$
Under bivariate normal assumption, the MLE of $\rho_{12}$
Interst in testing $H_0:\rho_{12}=0 \Leftrightarrow\beta_{12}=\beta_{21}=0$
Test statistic:
Interval Estimation: (when $\rho_{12}\not ={0}$)
CI for $\zeta=z’\pm z_{1-\alpha/2}\sqrt{\frac{1}{n-3}}=(c_1,c_2)$
CI for $\rho_{12}=(\frac{e^{2c_1}-1}{e^{2c_1}+1},\frac{e^{2c_2}-1}{e^{2c_2}+1})$
2.11.3 Spearman’s correlation method
Rank $(Y_{11},…,Y_{n1})$ from 1 to n and label:$(R_{11},…,R_{n1})$, rank $(Y_{12},…,Y_{n2})$ from 1 to n and label:$(R_{12},…,R_{n2})$.
Hypothesis: $H_0$: No Association Between $Y_1,Y_2\quad$v.s.$\quad H_A$: Association Exists
Test Statistic(when there is no tie):
Chap3 Diagnostics and Remedial Measures
Outline:
- Diagnostics for prediction variable
- Diagnostics for residuals
- Remedial Measures
3.1 Diagnostics for prediction variable
- Scatterplot
- Dot plot or bar plot
- Histogram or stem-and-leaf plot
- Box plot
- Sequence plot
3.2 Residuals
In a normal regression model we assume that
And we define residuals as
The properties of the residuals:
- $\sum_{i=1}^ne_i=\sum_{i=1}^nX_ie_i=\sum_{i=1}^n\hat{Y_i}e_i=0$
- $e_i$ are normal distributed but not independent. When n large, the dependency can be ignored.
Proof:
$e_i=Y_i-\hat{Y_i}\sim N(0,(1-h_{ii})\sigma^2),\quad cov(e_i,e_j)=-h_{ij}\sigma^2\not ={0},i\not ={j}$
where $h_{ij}=\frac{1}{n}+\frac{(X_i-\bar{X})(X_j-\bar{X})}{SS_{XX}}$
$\begin{aligned}var(e_i)&=var(Y_i)+var(\bar{Y})+var(b_1)(X_i-\bar{X})^2-2cov(Y_i,\bar{Y})-2(X_i-\bar{X})cov(Y_i,b_1)\\&=\sigma^2+\frac{\sigma^2}{n}+\frac{(X_i-\bar{X})^2\sigma^2}{SS_{XX}}-\frac{2\sigma^2}{n}-\frac{2(X_i-\bar{X})^2\sigma^2}{SS_{XX}}\\&=\sigma^2(1-\frac{1}{n}-\frac{(X_i-\bar{X})^2}{SS_{XX}})\end{aligned}$
Chap 5 Matrix Approach
5.1 Matrix properties
Trace: $tr(A)=\sum_i a_{ii}$
Idempotent: $A^2=A\Rightarrow A^n=A$
- A idempotent matrix is always diagonalizable and its eigenvalues are either 0 or 1.
- For an idempotent matrix, $rank(A)=tr(A)$ or the number of non-zero eigenvalues of $A$
- For $A_1,A_2$ are idempotent matrices
- $A$ is idempotent $\Rightarrow I-A$ is idempotent
5.2 Basic result
5.2.1 Variance-Covariance matrix
Suppose the random vector $Y$ consitsting of three observations.
5.2.2 Covariance matrix
Suppose the random vector $X$ consitsting of $m$ observations and $Y$ consisting of $n$ observations.
where $\sigma_{ij}=cov(X_i,Y_j)$
5.2.3 Expectation and variance
For constant matrices $A,B$ and random vector$Y$
If $E(Y)=\mu,var(Y)=\Sigma=(\sigma_{ij})$, then
Proof:
5.2.4 Multivariate Normal Distribution
Multivariate Normal Density function of $Y\sim N(\mu,\Sigma)$:
then $Y_i\sim N(\mu_i,\sigma^2_i),cov(Y_i,Y_j)=\sigma_{ij}$.
Note: if $A$ is a full rank constant matrix, then $AY\sim N(A\mu,A\Sigma A^T)$
5.3 Matrix Simple Linear Regression
Design matrix is defined as $n\times p$ matrix, with n observations and p variables
then the Linear Regression Model can be written as $Y=X\beta+\epsilon$ and $Y\sim N(X\beta,\sigma^2I)$
- $\epsilon\sim N(0,\sigma^2I)$
- $E(Y)=X\beta +E(\epsilon)=X\beta$
- $var(Y)=var(\epsilon)=\sigma^2I$
5.3.1 Some matrices properties
Note: $\sum_i X_i^2=\sum_i(X_i-\bar{X})^2+n\bar{X}^2$, so that
5.3.2 Estimating the parameters
Matrix derivation rules:
L2-loss is defined as:
Solve $\frac{\partial Q}{\partial \beta}=0$, which we obtain $X^TXb=X^TY\Rightarrow b=(X^TX)^{-1}X^TY$
so that $b\sim N(\beta,\sigma^2(X^TX)^{-1})$
5.3.3 Fitted value
Hat matirx:
where $h_{ij}=\frac{1}{n}+\frac{(X_i-\bar{X})(X_j-\bar{X})}{SS_{XX}}$.
Note: H is actually a projection matrix, which projects the observed value $Y$ onto the space that is spanned by the variables in $X$.
5.3.4 Properties of hat matrix
- Projection matrix: $HY=\hat{Y},HX=X,H\hat{Y}=\hat{Y},He=0$
- Symmetric: $H^T=H$
- Idempotent: $H^2=H$
5.3.5 Residuals
Note that the matrix $I-H$ is also symmetric and idempotent.
so that $e\sim N(0,\sigma^2(I-H))$
5.3.6 Analysis of Variance
Note that $Y^TY=\sum Y_i^2,Y^TJY=(\sum_iY_i)^2$
so that we have
Note that $H,\frac{J}{n},I-\frac{J}{n},I-H,H-\frac{J}{n}$ are idempotent and symmetric
Quadratic forms for ANOVA:
$SSTO=Y^T(I-\frac{1}{n}J)Y\sim \sigma^2\chi^2(n-1,\delta)$
$SSE=Y^T(I-H)Y\sim\sigma^2\chi^2(n-2,0)$
$SSR=Y^T(H-\frac{1}{n}J)Y\sim\chi^2(1,\delta)$
where $\delta=\frac{1}{\sigma^2}(X\beta)^T(I-\frac{1}{n}J)X\beta=\frac{\beta_1^2}{\sigma^2/SS_{XX}}$
Cochran’s Theorem(Corollary): Let $X\sim N(\mu,\sigma^2I)$, A is symmetric with $rank(A)=r$, and $\delta=\mu^TA\mu/\sigma^2$ then
Proof: there exists $A$ satisfies $A^TA=A^T(I-H)A=I_{n-p}$ ???
5.3.7 Inference in Regression Analysis
Parameters: use MSE to estimate $\sigma^2(b)$
Estimated mean response at $X=X_h$
$X_h=[1,X_h]$ then $\hat{Y}_h=X_hb$
Predicted new response at $X=X_h$
Chap 6 Multiple Regression I
Outline:
- Multiple regression models
- General linear regression model in matrix form
- Inference about regression parameters
- Estimation of mean response and prediction
- Diagnostic and Remedial Measures
6.1 Multiple regression models
- Can include polynomial terms to deal with nonlinear realtions
- Can include product terms for interactions
- Can include dummy variables for categorical predictors
First-order model with 2 numeric predictors:
here $X_1,X_2$ are additive and there is no interaction, $E(\epsilon_i)=0$
Interaction model:
here the effect of $X_1$ depends on level of $X_2$
General linear regression model:
which defines a hyperplane in p-dimensions. Here we assumes the error terms have Normality, Independence and constant variance $\epsilon_i\sim NID(0,\sigma^2)$
Other special types: dummy variables, polynomial terms, transformed response variable etc.
6.2 General Linear Regression Model in Matrix Form
Design matrix: same as Chap5, a $n\times p$ matrix
then we write $Y=X\beta+\epsilon$ and $E(Y)=X\beta, \sigma^2(Y)=\sigma^2I$
6.3 Estimation of Regression Coefficients
Least Squares Estimation:
Solve the equation $\frac{\partial Q}{\partial \beta}=0$ to obtain the estimator
Maximum Likelihood Estimation:
which leads to the same estimation as LSE since minimize $L(\beta,\sigma^2)$ are equivalent to minimize $Q$.
6.4 Fitted Values and Residuals
Hat matrix $H=X(X^TX)^{-1}X^T$ and fitted values $\hat{Y}=X\beta=HY\sim N(X\beta,\sigma^2H)$
Residuals $e=(I-H)Y\sim N(0,(I-H)\sigma^2)$
The properties of hat matrix is mentioned in Chap5.(Projection matrix, symmetric and idempotent, rank equals to p)
Denote that $H=(h_{ij})$, then
- $h_{ii}=\sum_j h_{ij}^2$
- $\sum_i h_{ii}=tr(H)=p$
- $\sum_i h_{ij}=\sum_j h_{ij}=1$
- $h_{ij}^2\leq h_{ii}h_{jj}$
- $h_{ii}\geq \frac{1}{n}$
Proof:
1- $H=H^2\Rightarrow h_{ii}=\sum_j h_{ij}h_{ji}=\sum_j h_{ij}^2$
2- $\sum_i h_{ii}=tr(H)=tr(H^TH)=p$
3- $HX=X$, compare the first column then we have $\sum_j h_{ij}=1$, then due to the symmetry of $H$, $\sum_i h_{ij}=\sum_j h_{ij}=1$
4- $h_{ij}=X_i(X^TX)^{-1}X_j^T$, since $(X^TX)^{-1}$ is positive definite, define the inner product $
5- Define $P=H-C$, where $C=\frac{1}{n}J$, then
$C$ is in the column space of $X$ since $span(1,…,1)\subset Col(X)$, $HC=C$. Also we know that $C=C(H+(I-H))$, $C(I-H)=0$ since $I-H$ projects onto $Col(X)^\perp$, then $C=CH$.
$P^2=H-C=P$ so $P$ is also a projection matrix, $h_{ii}=p_{ii}+c_{ii}=p_{ii}+\frac{1}{n}$ which means that $h_{ii}\geq\frac{1}{n}$
6.5 Analysis of Variance
Same as Chap5,
Cochran’s Theorem(Ch6page25)
here $E(MSR)\geq E(MSE)=\sigma^2$ and equal when all $\beta_i=0$
Hypothesis: $H_0:\beta_1=…=\beta_{p-1}=0\quad\text{v.s.}\quad H_1:\text{not all }\beta_i=0$
Test Statistic:
Adjusted R square:
6.6 Inferences about Regression Parameters
6.6.1 Independence of b and SSE
6.6.2 Parameters estimators
Since $b=(X^TX)^{-1}X^TY\sim N(\beta,\sigma^2(X^TX)^{-1})$, the variance can be estimated by
Denote $A=(X^TX)^{-1}=(a_{ij})$, then $b_k\sim N(\beta_k,\sigma^2(b_k))$, with $\sigma^2(b_k)=a_{k+1,k+1}\sigma^2$, then the variance estimator is
Since $b_k$ is independent with $SSE$,
then the CI for parameters can be constructed with
the simultaneous CI’s for $g\leq p$
Hypothesis: $H_0:\beta_k=0\quad\text{v.s.}\quad H_1:\beta_k\neq 0$
Test Statistic:
6.7 Estimating mean response & New observations
6.7.1 Estimating mean response
Given set of levels of $X_1,…,X_{p-1}$
the variance can be estimated by $s^2(\hat{Y}_h)=MSE(X_h(X^TX)^{-1}X_h^T)=X_hs^2(b)X_h^T$.
Note: We denote $X_h$ as a row vector, notice the difference beween here and textbook
Similarly, we have $\hat{Y}_h\perp SSE$,
CI for $E(\hat{Y}_h)$: $\hat{Y}_h\pm t(1-\frac{\alpha}{2};n-p)s(\hat{Y}_h)$
CI for g $E(\hat{Y}_h$: $\hat{Y}_h\pm B\cdot s(\hat{Y}_h)$
Confidence Region for Regression Surface: $\hat{Y}_h\pm W\cdot s(\hat{Y}_h)$
where $B=t(1-\frac{\alpha}{2g};n-p),W=\sqrt{pF(1-\alpha;p,n-p)}$
6.7.2 Prediction of New Observations
Predicted new response at $X_{new}=X_h$
$\hat{Y}_{h(new)}=X_hb\sim N(X_h\beta,\sigma^2X_h(X^TX)^{-1}X_h^T)$
Prediction error $Y_{h(new)}-\hat{Y}_{h(new)}\sim N(0,\sigma^2(1+X_h(X^TX)^{-1}X_h^T))$
the variance can be estimated by $s^2(pred)=MSE(1+X_h(X^TX)^{-1}X_h^T)$, such that
The prediction interval of $Y_{h(new)}$ is
Bonferroni: prediction interval for g $Y_{h(new)}$ is
6.8 Diagnostics and Remedial Measures
The methods are similar to simple linear regression. Here are some other different methods:
6.8.1 Scatterplot matrix
Summarizes bivariate relationships between $Y$ and $X_j$ as well as between $X_j$ and $X_k$
6.8.2 Correlation Matrix
Displays all pairwise correlations
6.8.3 Residual Plots
Plot $e$ vs $\hat{Y},X_j$ and missing variable. This is used for similar assessment of assumptions: Linear, Independence, Normality, Equal variance, omitted variables, outliers
6.9 Tests for Diagnosis
- Correlation test for normality
- Brown-Forsythe Test for Constancy of Error variance
- Breusch-Pagan Test for Constancy of Error variance
- F-test for Lack of fit
- Box-Cox Transformations
6.9.1 Breusch-Pagan Test
Hypothesis: $H_0:\sigma^2(\epsilon_i)=\sigma^2\quad\text{v.s.}\quad H_1:\sigma^2(\epsilon_i)=\sigma^2h(\gamma_1X_{i1}+…+\gamma_kX_{ik})$
Denote $SSE=\sum_i e_i^2$ from original regression, fit reression of $e_i^2$ on $X_{i1},…,X_{ik}$ and obtain $SS(Reg^*)$
Test Statistic:
6.9.2 Lack of Fit Test
This method is available when there are replicates in some X levels. Define X levels as $X_1,…,X_c$ with $n_j$ replicates respectively and $\sum_j nj=n$.
(reduced) linear model
$H_0:E(Y_i)=\beta_0+\beta_1X_{i1}+…+\beta_{p-1}X_{i,p-1}$
(full) there are c parameters $\hat{\mu}_j=\bar{Y}_j$
$H_1:E(Y_i)\neq\beta_0+\beta_1X_{i1}+…+\beta_{p-1}X_{i,p-1}$
Test Statistic:
when $H_0$ is rejected, a more complex model is required.
Chap 7 Multiple Regression II
Outline:
- Extra Sums of Squares
- General Linear Test
- Partial Determination and Partion Correlation
- Standardized Version of the Multiple Regression Model
- Multicollinearity
7.1 Extra Sums of Squares
Basic Ideas: An extra sum of squares measures the marginal reduction in the error sum of squares when one or several predictor variables are added to the regression model, given that other predictor variables are already in the model.(or the increase in the regression sum of squares)
For a given dataset, the total sum of squares (SSTO) remains the same. As we include more predictors, the regression sum of squares (SSR) increases and the error sum of squares (SSE) decreases.
Define extra sum of squares:
According to the Fisher’s Theorem:
where $\delta_{R_1}=\frac{1}{\sigma^2}SS_{XX}\beta_1^2,\delta_{R_2}=\frac{1}{\sigma^2}\sum\sum SS_{kl}\beta_k\beta_l$
and $\delta_{R_2}-\delta_{R_1}=0$, if $\beta_2=0$
Decomposition of SSR:
7.2 General Linear Test with Extra Sums of Squares
Situation: To test whether a single or several coefficients are zeros.
Example: First order model with 3 predictor variables
Full Model: $Y_i=\beta_0+\beta_1X_{i1}+\beta_2X_{i2}+\beta_3X_{i3}+\epsilon_i$
Reduced Model: $Y_i=\beta_0+\beta_1X_{i1}+\beta_2X_{i2}+\epsilon_i$
Hypothesis: $H_0:\beta_3=0 \quad v.s. \quad H_1:\beta_3\neq 0$
Test statistic:
for the first order model with 3 predictor variables,
Rejection Region: $F^*\geq F(1-\alpha;1,n-4)$
Similarly, to test whether several coefficients are zeros, the test statistic is:
Note: T-test is also appropriate for testing whether single coefficient is zero.
7.3 Summary of Tests Concerning Regression Coefficients
7.3.1 Test whether All $\beta_k=0$
The overall F-test:
7.3.2 Test whether Single $\beta_k=0$
The partial F-test:
7.3.4 Test whether Some $\beta_k=0$
The partial F-test:
7.3.5 Other Tests
Hypothesis: $H_0:\beta_1=\beta_2 \quad v.s. \quad H_1:\beta_1\neq \beta_2$
Reduced Model: $Y_i=\beta_0+\beta_c(X_{i1}+X_{i2})+\beta_3X_{i3}+\epsilon_i$
Hypothesis: $H_0:\beta_1=3,\beta_3=5 \quad v.s. \quad H_1:\beta_1\neq 3\text{ or }\beta_2\neq 5$
Reduced Model: $Y_i-3X_{i1}-5X_{i3}=\beta_0+\beta_2X_{i2}+\epsilon_i$
7.4 Coefficients of Partial Determination
Thus, $R_{Y1|2}^2$ measures the proportionate reduction in the variation in $Y$ remaining after $X_2$ is included in the model.(extra information proportion in the rest variance)
Similarly,
Coefficients of partial determination is between 0 and 1. square root of a coefficient partial determination is defined as:
Note: A coefficient of partial determination can be interpreted as a coefficient of simple determination. Suppose we regress $Y$ on $X_2$ and obtain the residuals:
then we further regress $X_1$ on $X_2$ and obtain the residuals:
The coefficient of simple determination $R^2$ for regressing $e_i(Y|X_2)$ on $e_i(X_1|X_2)$ equals $R_{Y1|2}^2$.
Thus, this coefficient measures the relation between $Y$ and $X_1$ when both of these variables have been adjusted for their linear relationship to $X_2$.
7.5 Standardized Regression Model
Numerical precision errors (Roundoff Errors) can occur when $(X^TX)^{-1}$ is poorly conditioned near singular:
- colinearity
- when the predictor variables have substantially different magnitudes
Standardized process can make it easier to compare effects of different predictors measured on different measurement scales.
7.5.1 Correlation Transformation
7.5.2 Standardized Regression Model
No intercept parameter: The least squares or maximum likelihood calculations always would lead to an estimation intercept term of zero.
Note:
1- Properties of $(X^)^TX^$
Note that
which equals to $r_{12}$.
2- Relation between $r_{XX},r_{XY}$ and $X^,Y^$
$r_{XX}$ is called the correlation matrix of the X variables, which has elements the coefficients of simple correlation between all pairs of the X variables.
$r_{XY}$ is a vactor containing the coefficients of simple correlation between the response variable Y and each of the X variables.
Then $(X^)^TX^=r_{XX}$, $(X^)^TY^=r_{XY}$.
3- Relationship between original coefficient and transformed coefficient
Chap 8 Quantitative and Qualitative Predictors
Outline:
- Quantitative predictors
- Qualitative predictors
- Polynomial Regression Models
- Interaction Regression Models
8.1 Polynomial Regression Models
Situation:
- True relation between response and predictor is polynomial
- True relation is complex nonlinear function that can be approximated by polynomial in specific range of X-levels
Second Order Model with One Predictor:
where $x=X-\bar{X}$
- $X$ is centered due to the possible high correlation between $X$ and $X^2$ (why?)
- $\beta_0$ is the mean response when $x=0$
- $\beta_1$ is called the linear effect
- $\beta_2$ is called the quadratic effect
Second Order Model with Two Predictors:
- $\beta_{12}$ is called the interaction effect coefficient
- Fitting with LSE (as multiple regression)
- Determine the order with some tests
- Extra Sums of Squares (one coefficient t-test or F-test)
- General Linear Test (F-test)
- Use coding in fitting models(centered/scaled) predictors to reduce multicollinearity
- Back-transform on original scale
8.2 Interaction Regression Models
Interaction: effect(slope) of one predictor variable depends on the level of other predictor variables (a unit increase in it depends on other variables)
8.3 Qualitative Predictors
Dummy variable: Represent effects of levels of the catigorical variables on response. For $c$ categories, create $c-1$ dummy variables, leaving one level as the reference category(avoid singular matrix)
For example, we have region category. We use dummy $X_2$ represent Region1, dummy $X_3$ represent Region2 and Region3 as reference
Controlling for experience:
- $\beta_2$ difference between Region1 and 3 (t-test or partial F-test)
- $\beta_3$ difference between Region2 and 3 (t-test or partial F-test)
- $\beta_2-\beta_3$ difference between Region1 and 2 (General linear test)
- $\beta_2=\beta_3=0\Rightarrow$ No differences among Region 1,2,3 with respect to $Y$ (Extra Sums of Squares)
Allocated Codes: Denote exact “weights” for each category
Indicator Variables: make no assumptions about the spacing of the classes and rely on the data to show the differential effects that occur
If we want to model interactions Between Qualitative and Quantitative Predictors, create cross-product terms between Quantitative Predictor and each of the $c-1$ dummy variables (test: General Linear Test)
Chap 9 Model Selection and Validation
Outline:
- Model-building process
- Criteria for model selection
- Search procedures for model selection
- Best subsets algorithm
- Stepwise, forward
- Model validation
9.1 Overview of model-building process
- Data collection and preparation
- Reduction of explanatory or predictor variables
- Model refinement and selection
- Model validation
Data Collection requirements vary with the nature of the study.
Controlled Experiments experimental units assigned to X-levels by experimenter.
(1) Purely Controlled Experiments: Researcher only uses predictors that were assigned to units.
(2) Controlled Experiments with Covariates: Researcher has information (additional predictors) associated with units.
Observational Studies units have X-levels associated with them (not assigned by researcher)
(1) Confirmatory Studies: new explanatory variables (primary variables), the explanatory variables that reflect existing knowledge (control variables) and the response variables
(2) Exporatory Studies: Set of petential predictors belived that some or all are associated with Y
Reduction of Explanatory Variables depends on types of the study
- Purely Controlled Experiments: rarely any need to reduce
- Controlled Experiments with Covariates: remove any covariates that do not reduce the error variance
- Confirmatory Studies: must to keep all control variables to compare with previous research, should keep all primary variables as well
- Exploratory Studies: need to fit parsimonious model that explains much of the variation in Y, while keeping model as basic as possible
9.2 Surgical unit example
9.3 Model Selection Criteria
- Likelihood of data (not sufficient, can always be improved by adding more parameters)
- Explicit penalization of the number of parameters in the model (AIC,BIC,etc.)
- Implicit penalization through cross validation
- Bayesian regularization (putting certain prior distribution on each model)
To find appropriate subset size: adjusted-$R^2$, $C_p$, PRESS, AIC, SBC
To find best model for a fixed size: $R^2$
9.3.1 $R^2$ and adjusted-$R^2$
$p=#\left\{\text{parameters in current model}\right\}$
9.3.2 Mallows’ $C_p$
Squared error for estimation $\mu_i$
It can be shown that the expected value is:
The total mean squared error for all $n$ fitted values $\hat{Y}_i$
The crieterion measure $\Gamma_p$
Consider the current model with $p-1$ predictors, we can show that
To estimate $\Gamma_p$, $\sigma^2,\sigma^2_Y,Bias^2$ need to be estimated
$C_p$ is the estimation of $\Gamma_p$
The model has no bias:
9.3.3 AIC and BIC
where $\mu_i=\beta_0+\beta_1X_{1i}+…+\beta_{p-1}X_{p-1,i}$
AIC adn BIC criterion are based on minimizing: $-2\log(L)+penalty$
9.3.4 $PRESS_p$
The PREdiction Sum of Squares quantifies how well the fitted values can predict the observed responses
where $\hat{Y}_{i(i)}$ is the fitted value for $i^{th}$ case when it was not used in fitting model.($\hat{Y}_{-i}$) It’s leave-one-out cross validation.
9.4 Automatic search procedures for model selection
9.4.1 Best subset search
Consider all the possible subset. For each of the model, evaluate the criteria. Time-saving algorithms have been developed, which require the calculation of only a small fraction of all possible models.(if $p>30$, it still requires excessive computer time)
9.4.2 Backward Elimination
Select a significance level to stay in the model (SLS). Start with all the variables, fit the full model with all possible predictors.
Consider the predictor with lowest t-statistic (highest p-value), if $p>SLS$ then remove the predictor and re-fit the model. Continue until all predictors have p-value below SLS.
9.4.3 Forward Selection
Select a significance level to enter the model (SLE). Start with no variables, add one variable with highest t-statistic (only if p-value < SLE). Continue until no new predictors have $p\leq SLE$
9.4.4 Stepwise Regression
9.5 Model Validation
Chap 10 Diagnostic for Multiple Linear Regression
Ouline:
- Model Adequacy for a Predictor Variable
- Identifying outlying Y
- Identifying outlying X
- Identifying Infuential Cases
- Multicollinearity Diagnostic
10.1 Model Adequacy for a Predictor Variable
Added-variable plots consider the emarginal role of a predictor variable $X_k$, given that the other predictor variables under consideration are already in the model. Both $Y$ and $X_k$ are regressed against the other predictor variables in the regression model and the residuals are obtained for each.
Suppose we are concerned about the nature of the regression effect for $X_1$, we regress $Y$ on $X_2$
then we regress $X_1$ on $X_2$
The added variable plot for $X_1$ consists of a plot of $e(Y|X_2)$ against $e(X_1|X_2)$, which represents the relationship beween $Y$ and $X_1$, adjusted for $X_2$
- $R^2_{Y1|2}$ equals to $R^2$ for regressing $e_i(Y|X_2)$ on $e_i(X_1|X_2)$
- Slope of the regression through the origin of $e_i(Y|X_2)$ on $e_i(X_1|X_2)$ is the partial regression coefficient $b_1$
10.2 Identifying outlying Y
The fitted model hat matrix $H=X(X^TX)^{-1}X^T$, then the residuals are $e=Y-\hat{Y}=(I-H)Y$
$\Rightarrow e\sim N(0,\sigma^2(I-H))$
10.2.1 Studendized residuals
Let $h_{ij}=(i,j)^{th}$ element of $H=X(X^TX)^{-1}X^T$, $h_{ii}=X_i^T(X^TX)^{-1}X_i$, $h_{ij}=X_i^T(X^TX)^{-1}X_j$, where $X_i=[1,X_{i1} … X_{i,p-1}]^T$
Studendized residual
10.2.2 Studentized Deleted Residuals
where $\hat{Y_i}_{(-i)}$ is the fitted value when regression is fit on the other $n-1$ cases
then $\hat{Y_i}_{(-i)}=x_i^Tb_{(-i)}$, here $x_i^T$ is the row vector of $X$
Studentized deleted residual
If there are no outlying observations,
Note: We can calculate $d_i$ and $t_i$ in a single model fit with
so that $MSE_{(-i)}=\dfrac{SSE}{n-p-1}-\dfrac{e_i^2}{(1-h_{ii})(n-p-1)}$
PREdicton Sum of Squares:
10.3 Outlying X-Cases
Hat matrix $H=X(X^TX)^{-1}X^T=(h_{ij})$, let $x_i^T=[1,X_i]$, then
Some properties of hat matrix:
- $\sum h_{ii}=trace(H)=p$
- $HX=X\Rightarrow\sum_{i=1}^n h_{ij}=\sum_{j=1}^n h_{ij}=1$
- $H=HH\Rightarrow h_{ii}=\sum_{i=1}^n h_{ij}h_{ji}\geq 0$
- $(I-H)^2=I-H\Rightarrow 1-h_{ii}=\sum_{j=1}^n (I_{ij}-h_{ij})^2\geq 0$
Leverage Values:
Leverage of ith case $h_{ii}$ measures the distance beween the $X_i$ value and the mean of the $X$ values. The closer the case to the “center” of the sampled X-levels, the smaller the leverage is.
Large leverage values: $h_{ii}>2p/n$
Also, $h_{ii}$ is a measure of how much $Y_i$ is contributing to the prediction $\hat{Y_i}$. Case with large leverages have the potential to “pull” the regression equation toward their observed Y-values.
10.4 Identifying Influential Cases
Type of unusual observations:
- Unusual Y value has little influence
- High leverage has no influence
- Combination of dicrepancy (unusual Y value) and leverage (unusual X value) results in strong influence
10.4.1 Difference between the fitted values (DFFITS)
where $h_{ii}$ is estimated sd of $\hat{Y}_i$
DFFITS measures the influence on single fitted value:
- for small data sets, influential if $|DFFITS|>1$
- for large data sets, influential if $|DFFITS|>2\sqrt{p/n}$
10.4.2 Influence on all fitted values (Cook’s Distance)
where $\widetilde{e}_i=\frac{e_i}{\sqrt{MSE(1-h_{ii})}}$ is studentized residual
Problem cases are $D_i>F(0.5;p,n-p)$
10.4.3 Influence on the Regression Coefficients (DFBETAS)
where $c_{kk}$ is the k-th diagnal element of $(X^TX)^{-1}$
Problem cases are $DFBETAS>1$ for small data sets, $DFBETAS>2/\sqrt{n}$ for large data sets
10.5 Multicollinearity
- Standard errors of regression coefficients increase
- Individual regression coefficients are not significant
- Point estimates of regression coefficients are wrong sign
Considering the standardized regression model, we have $X_{ik}^*=\frac{1}{\sqrt{n-1}}(\frac{X_{ik}-\bar{X_k}}{s_k})$
then $\sigma^2(b_k^)=(\sigma^)^2(VIF)_k$, where $(VIF)_k$ is the k-th diagonal element of $r_{XX}^{-1}$
Variance Inflation Factor(VIF):
where $R_k^2$ is the coefficient of determination when $X_k$ is regressed on the $p-2$ other $X$ variables (how much variance of $X_k$ is explained by the other variables). $1\leq VIF\leq\infty$
$\max((VIF)_1,…,(VIF)_{p-1})>10$ indicates there is serious multicollinearity problem
Chap 11 Remedial Measures
Outline:
- Weighted Least Squares(unequal error variance)
- Ridge Regression(multicollinearity)
- Robust Regression(influential cases)
- Lowess & Regression Trees(nonparametric)
- Bootstrapping(evaluating precision)
11.1 Weighted Least Squares
Since the unequal variance, we set different weights on each variable $w_i=\frac{1}{\sigma_i^2}$
To maximize $L(\beta)$, we need to minimize $Q_w=\sum w_i(Y_i-\beta_0-…-\beta_{p-1}X_{i,p-1})^2$
Set up the weight matrix:
$\sigma^2(Y)=\sigma^2(\epsilon)=W^{-1}$
Normal equations: $(X^TWX)b_w=X^TWY$
When the variances are unknown, we need to estimate the variance:
- Estimation of variance function or standard deviation function(Breusch-Pagan Test)
- Use Replicates or Near Replicates(sample variance of replicates)
- Use squared residuals or absolute residuals from OLS to model their levels as funcions of predictor variables(regress absolute residuals on X and use the fitted value)
11.2 Ridge Regression
Standardized Regression:
Ridge Estimator:
which is equivalent to minimize
Then we can obtain $VIF$ by
$VIF_k$ is the k-th diagonal element of $(r_{XX}+cI)^{-1}r_{XX}(r_{XX}+cI)^{-1}$
11.3 Robust Regression
- Least Absolute Residuals(LAR) or Least Absolute Deviation(LAD): Choose the coefficients that minimize sum of absolute deviations
- Iteratively Reweighted Leaste Squares(IRLS)
Median Absolute Deviation (Robust estimate of $\sigma$)
$median|\frac{\xi-\mu}{\sigma}|=\Phi^{-1}(0.75)\approx 0.6745$
since $median|Z|=c \Leftrightarrow P(-c\leq Z\leq c)=0.5$
Chap 14 Logistic Regression with Binary Response
Outline:
- Odds Ratio
- Modeling binary outcome variables
- The Logsitic Model
- Inferences about regression parameters
14.1 Odds Ratio
A binary response variable $Y$ which takes on the values 0 or 1. The parameter of interst is $\pi=P(Y=1)$
Odds: $Odds(\pi)=\frac{\pi}{1-\pi}=\frac{P(Y=1)}{1-P(Y=1)}$
we can see $Odds<1\Leftrightarrow\pi<0.5$
Odds ratio: We are usually intersted in comparing the probability of $Y=1$ across two groups
14.2 Modeling binary outcome variables
14.3 The Logistic Model
Sample: independent $Y_1,Y_2,…,Y_n.Y_i\sim B(1,\pi_i)$
Logistic mean response function:
which can be linearized using logit transformation:
14.3.1 Simple Logsitic Model
$Y_i$ are independent Bernoulli random variables with mean $\pi_i=E(Y_i)$
14.3.2 Multiple Logistic Model
Suppose there are $n$ observations and $p-1$ variables, then the design matrix has $n\times p$ size.
where
The log likelihood
14.4 Inferences about Regression Parameters
Maximum likelihood estimators for logistic regressioin are approximately normally distributed, with little or no bias.
14.4.1 Wald Z-test
Hypothesis: $H_0:\beta_k=0\quad\text{v.s.}\quad H_1:\beta_k\neq 0$
Test statistics:
If $|z^*|>z(1-\alpha/2)$, reject $H_0$
CI for $\beta_k$: $b_k\pm z(1-\alpha/2)s(b_k)$
CI for odds ratio $\exp(\beta_k)$: $\exp[b_k\pm z(1-\alpha/2)s(b_k)]$
Bonferroni joint CIs for $g$ logistic parameters: $b_k\pm z(1-\alpha/(2g))s(b_k)$
Wald Chi-square:
$\xi\sim N(\mu,\Sigma)$ and we find $(\xi-\mu)^T\Sigma^{-1}(\xi-\mu)\sim\chi^2(k)$
then we write
14.4.2 Likelihood Ratio Test
Testing a subset of parameters:
Review LRT:
$H_0:\theta\in\Theta_0\quad\text{v.s.}\quad H_1:\theta\in\Theta_1=\Theta\backslash\Theta_0$
Under $H_0$, $-2\ln\Lambda=-2[\ln L(\hat{\theta}|H_0)-\ln L(\hat{\theta})]\sim\chi^2(k)$, where $k=\dim(\Theta)-\dim(\Theta_0)$
Final Test Review
- Hat matrix properties: traceH=p, projection
- partial determination
- Qualitative predictors
- regression with intersection
- VIF and correlation coefficient
- Six Criteria, stepwise(describe)
- Logistics (OR,Likelihood,Inference)
Remedial Measures: collinearity, outlier, ommited?
Hat matrix projection:
$HX=[H1,HX_1,HX_2,HX_3]=[1,X_1,X_2,X_3]=X$. If new variable $X_4$ is added in, it doesn’t satisfy $HX=X$, unless $X_4$ is a linear combination of $1,X_1,X_2,X_3$